
前置约定
把B的脸换到A上。
A:脸应该被替换的数据集
B:用于替换A的脸的数据集
数据集
数据集要求:
Training Data
It cannot be overstated enough how important the quality of data is to your model. A smaller model can perform very well with decent data, similarly no model will perform well with poor data. At an absolute minimum there should be 500 varied images in each side of your model(A和B每边至少要500张), however the more data, and the more varied, the better… up to a point.A sane number of images to use is anywhere between 1,000 and 10,000(数量). Adding many more images than this can actually hurt training.
Too many similar images will not help your model.You want as many different angles, expressions and lighting conditions as possible(不同角度,不同表情,不同灯光). It is a common misconception that a model is trained for a specific scene. This is “memorization” and is not what you are trying to achieve. You are trying to train the model to understand a face at all angles, with all expressions in all conditions, and swap it with another face at all angles, with all expressions in all conditions. You therefore want to build a training set from as many different sources as possible for both the A and B set.
Varied angles for each side are highly important. A NN can only learn what it sees. If 95% of the faces are looking straight at the camera and 5% are side on, then it will take a very long time for the model to learn how to create side on faces. It may not be able to create them at all as it sees side on faces so infrequently. Ideally you want as even distribution as possible of face angles, expressions and lighting conditions.
Similarly, it is also important that you have as many matching angles/expressions/lighting conditions as possible between both the A and B sides(最好是A和B的采样是相似的). If you have a lot of profile images for the A side, and no profile images for the B side, then the model will never be able to perform swaps in profile, as Decoder B will lack the information required to create profile shots.
The quality of training data should generally not be obscured and should be of a high quality (sharp and detailed). However, it is fine to have some images in the training set that are blurry/partially obscured. Ultimately in the final swap some faces will be blurry/low resolution/obscured, so it is important for the NN to see these types of images too so it can do a faithful recreation.
More detailed information about creating training sets can be found in the Extract guide.
数据集预处理
训练
粗训
先跑个10w Iteration
细训
勾选NoWarp
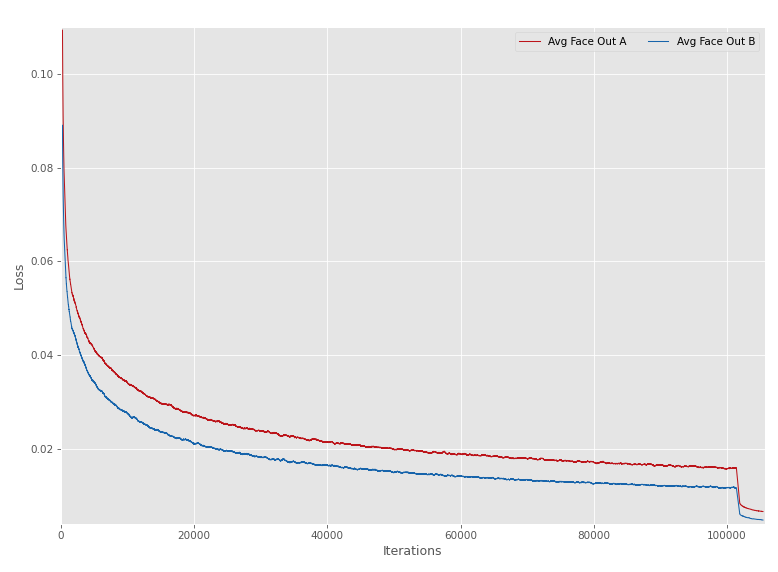
loss值
参考
faceswap Forum:https://forum.faceswap.dev/index.php
